
Design page-based content models
About this guide
This page is a part of the Content modeling guide which you should follow sequentially from beginning to end. You can also follow this series in Content modeling guide, which helps you keep track of your progress as you move through this sequential material.
From a marketing perspective, not all content will be distributed across multiple marketing channels. The page-based model works perfectly in situations when semantically defined content is displayed under one specific URL.
In projects that embrace a page-based content model, editors save, structure, and manage content as individual pages within a website channel. They use the Page Builder to display content from the Content hub or add content directly to the page.
Understand how editors work with page content in Xperience
Compared to other CMS solutions where website pages and their storage capabilities are used for creating one-off, non-reusable content, storing content in Xperience webpage content types doesn’t mean that this content is available only when a user visits a specific page.
If the webpage content is stored in structured format, editors can use this page-specific data across the website channel where they create the page, refer to it from other website channels, or share it through emails.
Typical Xperience projects built with the page-based approach contain pages with structured fields in Content view mode and the Page Builder.
Editors capture data they want to reuse as structured data (in the Content view or as content items in the Content hub). They then use the Page Builder’s easy-to-work-with drag-n-drop interface and display this page data on the same page, across other website pages, or in emails. Page Builder widgets allow them to retrieve reusable content items or content blocks content from the Content hub, for example, a Hero banner or other content fragments, such as a collection of questions and answers for a QA page, in the Content hub.
Editors can compose layouts in a WYSIWYG manner, giving the content clear visual meaning and hierarchy. In the backend, the Page Builder components help editors communicate the content’s semantics and structure in a way that is understood by search engines, screen readers, and other systems.
The following example shows a product page on the Kbank website. Though this website page is built using atomic content model, this page uses structured data and Page Builder to display it.

As you can see, the product detail page is composed of multiple structured sections and widgets, each representing a different part of the layout.
At the top, the Hero banner section introduces the product with a large headline, supporting text, and a featured image. Below it, a Summary or promo section presents a short description of the product that’s followed by Product highlights section. This section combines an image with a styled content block that includes key features, and a list of product details.
Further down, a Promotion widget in a dedicated section displays a standalone promotional message that’s accompanied with an image. The page also includes an FAQ section with collapsible items, allowing users to explore common questions.
Beneath the FAQs widget, the page is split into two columns. The left side uses Benefits widget to list additional product benefits in a bulleted list. The rigth side contains a Card widget wiht an image and links to a news article about the product.
Lower on the page, a full‑width image section provides a visually rich break in the layout. Near the bottom, a lead‑capture form section lets users submit their contact information.
Finally, the page ends with a footer section that contains navigation and branding components. All these components together create a structured, modular product page assembled from reusable content items and page‑builder widgets.
Learn why the page-based model works for web-first projects
The page-based content model best fits projects with a dominant, single website channel, where editors plan to use this website content in emails or a few micro-channels.
When an editor thinks, “I’m creating and publishing a page that users can navigate to using a URL,” their workflow can be much simpler. It feels natural, and looking at the page, the editor has all the necessary context. They have a clear picture of the content’s layout, they understand its structure and purpose within the website channels, especially if they come to Xperience from traditional CMS solutions.
Consider also the following benefits:
- The page-based content model supports campaign workflows well. It is easy to create, clone, and manage landing pages, and editors can reference structured content in related newsletters or campaign emails as needed. This flexibility allows teams to react quickly when campaign requirements change.
- Curating existing media and other assets becomes simpler. Editors usually update their content from within the page context and refer to assets directly from the specific pages using the Content view mode or, more likely, the Page Builder widgets.
- A page-based workflow makes onboarding easier. Editors see their content in context, which reduces new users’ training time.
Let’s discuss key aspects of defining a page-based content model.
Always focus on the editor workflow
Data in page-based, web-centric projects closely reflects the visual experience.
When you define content types for a page-based content model, start by examining the website designs provided by your graphic design or UX teams. Consider how editors naturally want to assemble this page and aim to support their workflow without unnecessary friction.
Ask: If I were an editor, how would I want to put together this page? Which parts of this page do I want to use somewhere else? Which components do I need to build this page?
Editors will create pages from the website channel. They first select the content type, then a page template that contains editable areas for sections with widget zones where they place widgets.
Looking at the design from the editor’s workflow perspective will help you identify which content can editors add directly in the Page Builder, which should be added in the Content view, and which parts of the page need to become reusable Content hub items.
Your goal is to minimize how often editors need to switch between the Content tab and Page Builder while creating related content.
Then, look at the content pieces from a higher perspective and think:
Which pieces of content will editors create before they build this page? What they need to have ready in advance before they start working on this page? Which data will they put together at once? What content will they likely work on after they finish this page?
This helps ensure editors won’t need to switch between the Content view mode and Page Builder context to complete related tasks. Aim for a seamless workflow that keeps the editor in the context of one editing UI as long as possible.
When you decide which content will be stored in fields, define visibility conditions to improve editor workflow. This will allow hiding advanced design and introducing configuration options by default. Editors will work in a clean, focused editing interface that reduces potential errors and confusion.
Identify reusable data
When an editor stores data into the page, the content becomes “owned” by the page. It is always navigable under the page-specific URL, and in case of storing data in the Page Builder, this data is not easy to reuse.
At the same time, editors will want to share bits and pieces of their content strategically across their website, on additional microsites, or emails. They also want to ensure their website data adheres to the traditional SEO requirements.
Identify data that needs to be reusable across pages or channels. Look for content structured by nature, such as titles, summaries, addresses, opening hours, pricing tables, or product feature lists. Check the examples of semantic content types that reflect real-life use cases.
Determine what structured data is needed to construct data for semantic SEO, which data will editors want to display in multiple places and make sure that this data is stored in a structured form in the Content view.
Determine the structured data needed to construct web page’s rich metadata:
- JSON-LD metadata for traditional SEO,
- OpenGraph metadata for social media,
- newly proposed LLMs-txt standard,
- shared web page data editors want to display in multiple places, and ensure that this data is stored in a structured form in the Content view.
Website editors might want to overwrite the default, core content values stored in the website data field. Also plan for fields to override publishing dates or other system-generated values to help editors’ needs. Editors can reuse this structured data across different channels or websites, so consider how it will be modeled to allow controlled reuse without disrupting the page-based workflow.
Finally, identify data that may originate from external systems, such as pricing data or product specifications, and plan how to import or reference this data within your content types while maintaining consistency and reliability for editors working in the page-based model.
When deciding between reusable and channel-specific content, follow a simple rule of thumb:
Can editors reuse this piece of content on a different channel in the future? If yes, make it reusable and store it either in the Content view mode or in the Content hub.
Manage media assets from the Content hub
We recommend using the Content hub to manage reusable images, videos, and other assets and organize them in folders and a workspace structure. In a page-based content model, editors should be able to manage all their content from their website channel. Images and other assets are no exception.
Design the editing flow with built-in components so the editor can upload any new assets they need for a page from within the edited page. Your developers configure widgets and content fields, so that editors can upload or select their assets using dedicated Content hub folder and workspace.
To bulk-upload images, editors will use the mass upload feature in Content hub.
Extract shared data to a reusable schema
Multiple pages will likely repeat the same fields across different content types that you can store into reusable field schemas.
This core content typically includes information, such as title, summary, taxonomy, or a thumbnail image. Reusable field schema reduce data duplication, simplify content type management, and improve the editor experience. Content types with reusable field schemas are transparent and predictable. The data is stored in one of the core content item database tables, which helps developers optimize the performance of retrieving this data.
At the same time, combined content selector allows editors to select items that share the same reusable field schemas, which simplifies content management and might require fewer widgets to display this content.
See core content schema for a deeper explanation and best practices for how to store core content into reusable field schemas.
Define page-specific one-off content
Not all content needs to be reusable. Content like personalized call-to-action button labels or page headings will likely be specific only to the website channel, and it doesn’t have to exist as reusable content in the Content hub or as structured data within pages. Editors will create these items directly for a specific website page and keep them there.
Besides adding reference to reusable structured data, editors can input content into widgets in two ways: through widget properties that display in the side panel view or in a WYSIWYG manner using widget inline editing.
Make widgets respect content hierarchy
Provide widgets for one-off page content that editors will can to add one-off content. Your widgets should reflect project needs and ensure that input data maintains its structural hierarchy and semantic clarity. These widgets should support content such as tables, visual journeys, or step-by-step instructions. These widgets should generate semantic HTML and enforce consistent formatting across all pages.
Design Page Builder components to guide editors in creating pages that output valid, semantic HTML with clear structures like heading hierarchy or correctly identified content sections. This ensures consistent, accessible, and SEO-friendly pages without requiring editors to manage technical details manually. Learn more about how to prepare your content for SEO and AI readiness.
Integrate rich text editing when necessary
Sometimes, projects require almost free-form WYSIWYG text editing with advanced styling options like formatting text, adding tables on the fly, or even adjusting the HTML markup. This usually happens when the editor team is upgrading to Xperience from an older kentico Portal Engine website where they used to work with editable text or comes to Xperience from another CMS platform.
You can use the built-in rich text to create the most flexible editing experience.
At the same time, remember: the page owns the content in the Rich text widget. It’s hard to reuse elsewhere because it isn’t structured and can’t be easily queried or shared across channels. It exists on the page’s URL, which makes it non-reusable across different channels.
If editors use the HTML editing mode, the designs they introduce can be more complicated to update (e.g., the company updates its brand messaging). During the content modeling session, your team should discuss and agree on rich text editor configuration to only allow desirable HTML attributes and tags.
Remember, all content added directly to a Page Builder widget is stored in a single database field, which makes it difficult to reuse this content.
While editors are used to working with rich text editors and they will likely ask for it in project requirements, always consider its implications in the content modeling sessions. Allowing editors to input rich text data or update significantly impacts content reusability and the project’s longevity when, for example, the company changes its brand manual. There are situations where rich text is completely fine, and there are cases in which a dedicated, slightly more restrictive widget will help maintain content longevity and improve maintainability.
For example, if the editor team knows how to keep the document structure intact to help technical SEO, they can safely use the Rich text widget to add page headings. In other cases, it might be helpful to create, for example, a dedicated widget. As you can see below in the Kbank demo site’s Page heading widget, editors can select the heading HTML tag, but override its default visual size in a dedicated dropdown.
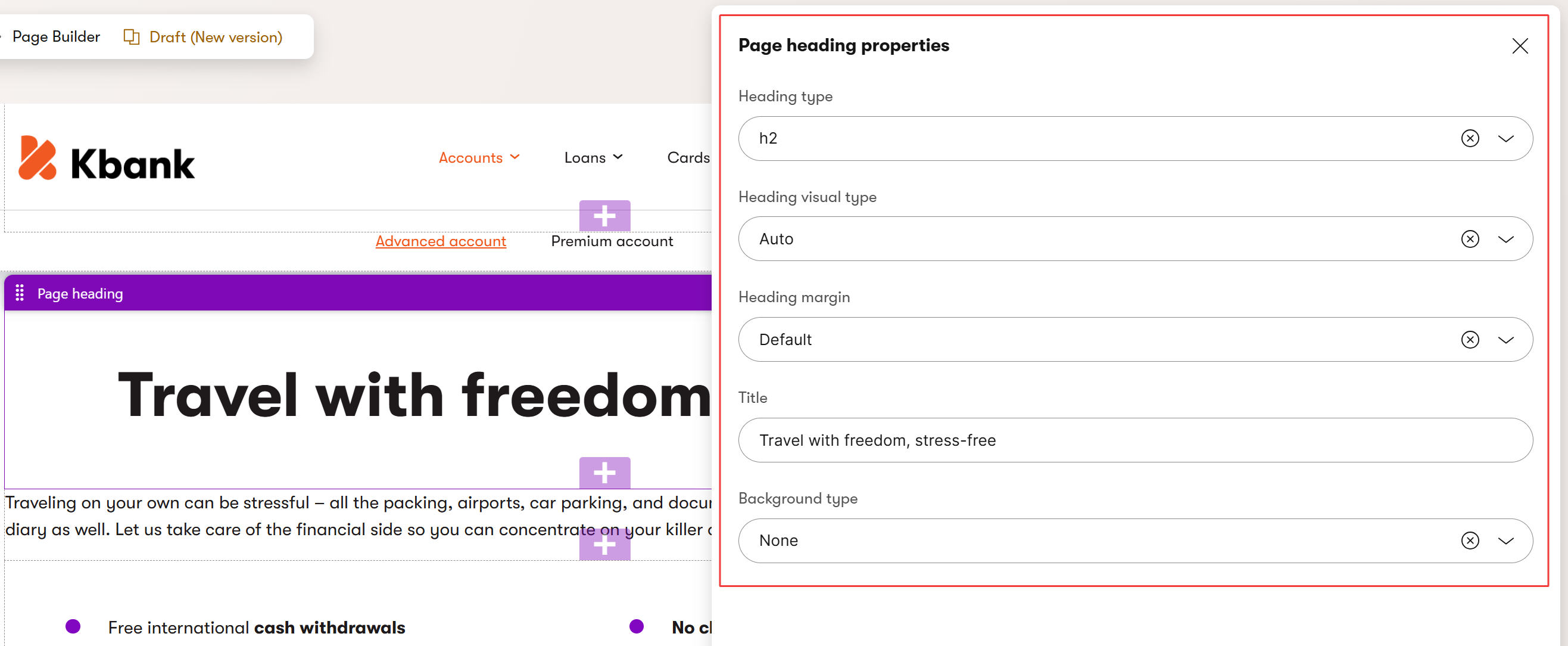
Consider creating a custom markdown widget
In general, we recommend storing content that has to stay consistent and presentation agnostic in structured format, either in Content view mode or using the Content hub.
If you need to create a WYSIWYG editing experience but have to withhold data structure when editors add it to the page (for example, to display it in external systems), consider creating a custom Markdown widget to keep page data in a highly portable format. Editors will gain a free-from-like editing UI, and developers will have a slightly easier way to query the data in their custom API. See the Markdown widget in the Kentico Community Portal.
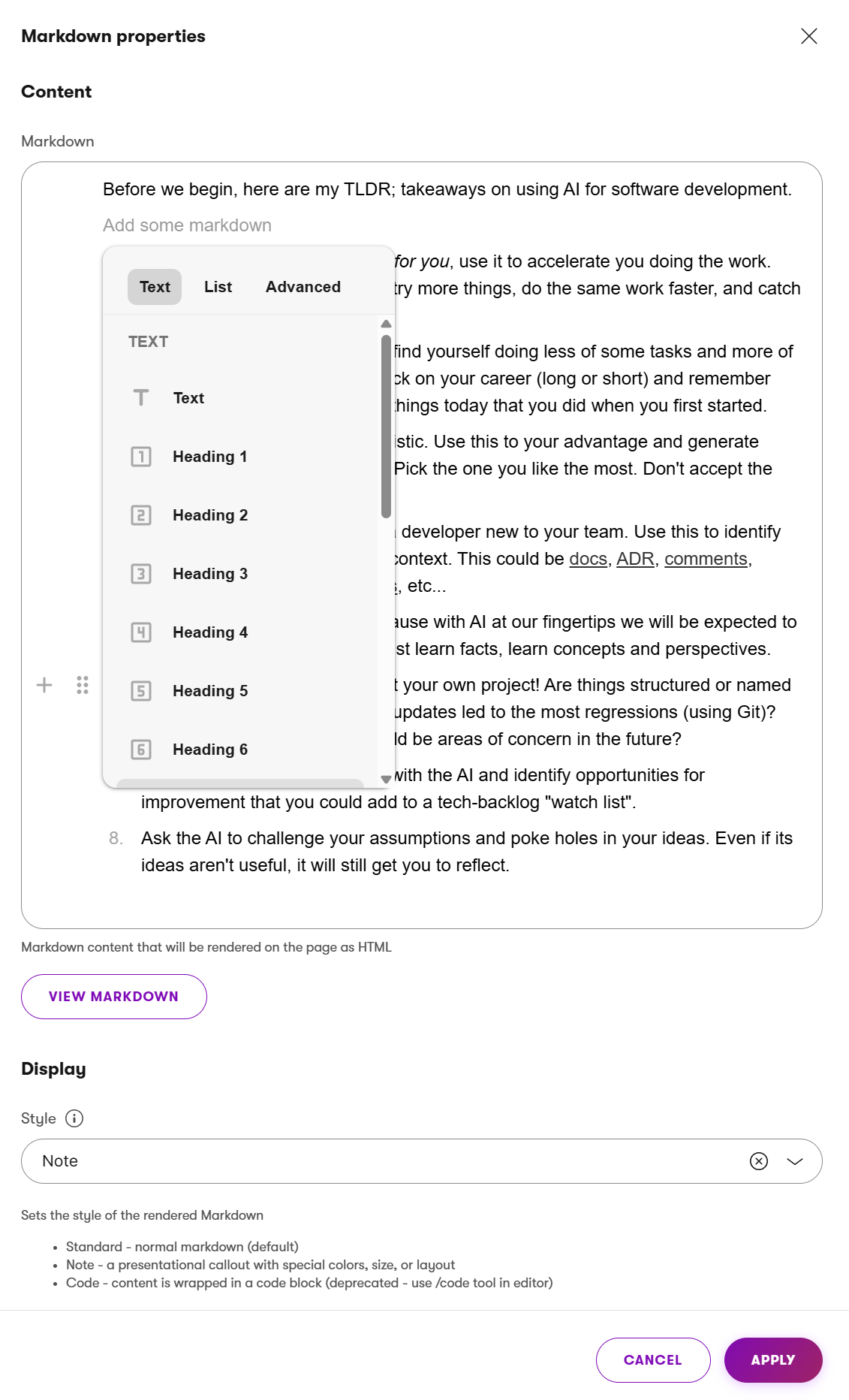
Editors create content in a large Content area and use standard Markdown tags or WYSIWYG styling in dropdown to create the content. Below, they can configre the layout of the content and make it a Note, Code block or a Standard text.
Restrict access to widgets in page templates
To support a page-based model, define Page Builder page templates that match your intended semantic content types. Each template should provide clear areas aligned with your design files, with widgets and section editors that users are allowed to use. You can find different examples of widgets and other recommendations for displaying content on a dedicated page.
Connect webpages with Content hub reusability
Some projects may require setting up content filters to improve the editors’ workflows or deliver content dynamically, based on, for example, publishing date or taxonomy. The features that enable this, such as advanced filtering and smart folders, are not yet available for the website channels.
To connect a web page with page-specific content with the reusable, channel-agnostic capabilities of the Content hub, we recommend creating a Page proxy content type. The page proxy represents a specific webpage within a website channel inside the Content hub, containing only a single field with Combined content selector to create the reference that you can see in the following image. Thus, you’ll allow editors to take advantage of Content hub features that are not available to Xperience website channels.
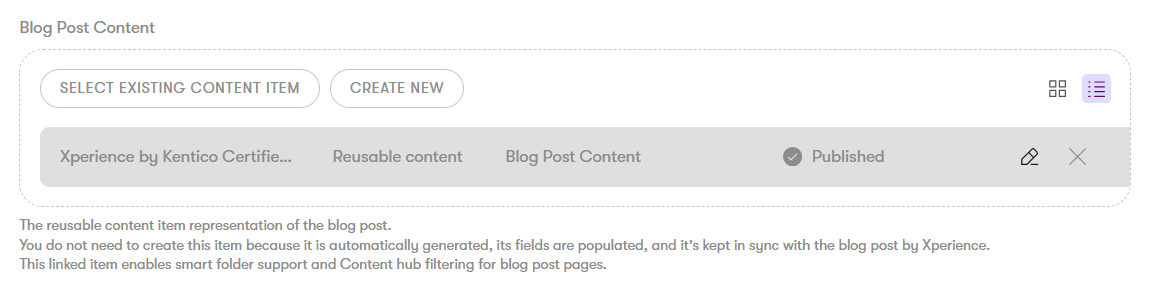
The page proxy pattern helps in scenarios where specific page types need to participate in Content hub workflows, such as using smart folders for dynamic content delivery, creating content collections using Content hub folders for filtering, or reusing specific taxonomy tags across related content.
Note that Page proxies are unnecessary for every page type and should be used only where the benefits of connecting with the Content hub are clear.
Developers can also custom-build a feature that automatically creates its page proxy when an editor makes a page in a website channel. This will improve the editor workflow and ensure the page proxy pattern remains in sync with the source page.
You can inspect the page proxy pattern and its implementation on the Kentico Community Portal.
Address challenges in a page-based model
When you build a page-based content model, you may run into challenges that limit flexibility, scalability, or content reuse. This section explores practical approaches to mitigate common issues, helping you maximize the use of Xperience’s capabilities while maintaining a clean, maintainable content structure.
|
Challenge |
How to address |
|
Inconsistent structure |
Provide semantically structured widgets with enforced HTML tags and ARIA labels. |
|
Limited cross-channel reuse |
Use Content hub for reusable, non-navigable content. |
|
SEO and AI readiness |
Use structured data fields (JSON-LD), validate with accessibility and SEO tools. (Use external tools until the Xperience AIRA receives related features.) |
|
Content fragmentation |
Use placeholder widgets to enable referencing structured content within pages. |
|
Taxonomy underuse |
Plan taxonomy structures and enforce tagging during content creation. |
|
Workflow friction |
Group related fields in the Content view mode to reduce context switching and UI information overload. |
Add widget properties for overriding reusable values
Making content reusable doesn’t mean editors are limited to always displaying the core reusable values. They need a flexible editing experience. They need to tweak parts of the content when they display it on one page, and adjust different parts when they display it somewhere else.
When you look at the
Since you have reusable content you have in identified, ask yourself:
Which of these reusable page structured data will editors want to overwrite, for example, in personalization variants? Which of this data will they want to move or style on the page?
Improve the editing experience and define the Page Builder widget with properties that will allow editors to overwrite the core values without modifying the source data. For example, when an editor selects content to feature in a card using Combined content selector, they will want to overwrite the core content description with a message that better fits their needs using dedicated widget property fields, such as custom title or a short description, as the following image of Featured content widget properties illustrates.
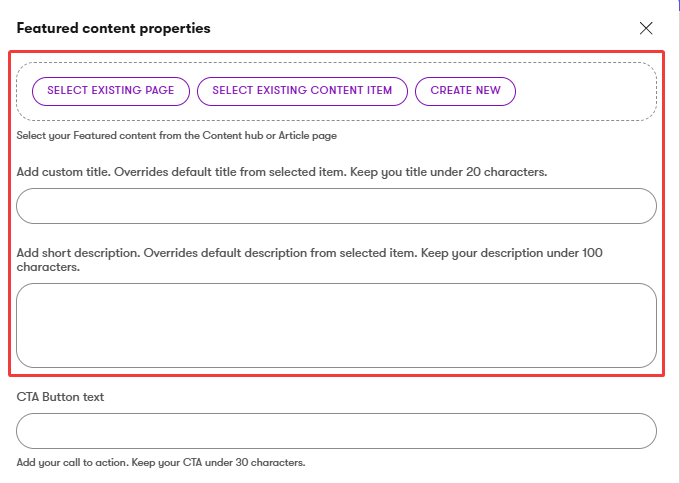
Use taxonomies to systematically categorize and surface related content while ensuring your content model supports filtering without additional complexity. Include structured metadata fields in the Content tab to handle SEO, Open Graph, and JSON-LD requirements, maintaining consistency and machine-readability across all pages. Finally, while allowing rich text fields where flexibility is needed, consider Markdown or structured text fields for content requiring uniformity and easier reuse.
Avoid creating channel-specific content from linked content fragments
Building pages with the Page Builder is addictive which also creates a trap. You might be tempted to define one or two universal page templates with widgets and let editors assemble any content using one-off or reusable data from Content hub.
This free-form approach works well for short-lived, campaign-style pages. Editors create content quickly and iterate quickly over the page’s layout and data.
But free-form pages can become a liability for anything beyond a campaign page. When editors compose content from non-semantic content fragments (hero, text block, testimonial, FAQ), they’re assembling presentation but don’t create meaningful content item. The combination of individual fragments lives only within the page where they were placed.
Editors create a semantic content items in the website channel. The Xperience API doesn’t offer methods that allow developers to reliably query this data, so editors won’t be able to reuse their content effectively.
The result is channel-locked content that’s hard to adapt to mobile apps, emails, search, or API consumers. What starts as flexibility turns into fragmentation: editors need to double down on duplicated content, and when they miss anything, their messaging might not be consistent. Instead, prefer Page Builder for layout and campaign agility and introduce structured data to support consistent and reusable delivery.
Leverage built-in taxonomies
Building your entire digital experience within the website channel using page-based data can lead to under-utilizing Xperience’s taxonomy feature. If you’re coming from older Kentico products, you may be used to categorizing the content using the content tree hierarchy in the website content model. However, relying solely on the content tree for categorization can limit how effectively you use Xperience’s full capabilities.
Instead, consider how you can leverage built-in taxonomies effectively. Review your content taxonomy to determine which categories should be structured within the content tree—such as business areas that align with your site’s navigation—and where tagging can enhance your global taxonomy, such as image categories, article categories, persona-specific content, or campaign data.
This approach will help you integrate taxonomies naturally into your editor workflow, and ensure that editors categorize content with identical tags during content creation. Using taxonomy tags, developers then leverage leverage taxonomy API for more flexible retrieval, filtering, and organization.
Optimize for SEO and AI
The traditional SEO landscape is evolving fast thanks to the AI-driven innovations. Ignoring the new trends or forgetting about the traditional technical SEO rules and practices can significantly influence the application’s discoverability.
Ensure your content is ready for AI-driven discovery and SEO. You need to deliberately architect your page-based model to adhere to existing conventions.
Make sure that every page has a way to store necessary metadata. Use reusable field schema in the Content view to provide fields for SEO, Open Graph, and other systems and frameworks that the project needs to support.
Front-end designers need to orchestrate the Page Builder components so that the markup they provide returns correct semantic HTML elements such as main, article, or section elements and that the page’s content hierarchy follows web standards, making the content structure ready for search engines, accessibility tools and AI agents.
Developers need to consistently apply structured metadata to maintain a transparent, machine-readable data layer across all pages.
Since AIRA content capabilities are evolving, we recommend integrating a 3rd-party solution to validate your pages using SEO and accessibility tools as part of your publication workflow. Also, specialists should periodically review website content and markup to ensure editors follow structured data practices. They need to align the digital content with evolving search engine requirements and ensure your content remains discoverable within AI-driven search contexts.
What’s next?
You’ve learned how to define a page-based content model to help editors understand and manage their content. They will store most of their data in website channel pages and put all reusable content, including images and other assets, in the Content hub. In the next section, you’ll learn about creating a highly reusable content experience using atomic content model. You’ll learn how to build a model that makes the core content independent of any presentation layer and allows strategic reuse across different systems.