
Retrieve headless content
Features described on this page require the Xperience by Kentico Advanced license tier.
Every headless channel in Xperience by Kentico provides a GraphQL API endpoint, which allows you to retrieve content using HTTP requests and the JSON data format. Such headless content can be displayed or otherwise consumed by various types of applications, services or websites (e.g., mobile apps, external websites, single-page applications running within Xperience, etc.).
Before you can retrieve content using the headless API, you need to:
- Set up headless channels.
- Define content types for headless content.
- Add the required content by creating headless content items.
Once your headless channels are configured and the content is ready, you can:
- Explore the GraphQL schema and prepare queries for the desired content.
- Retrieve the content from your consuming applications or services by sending requests to the headless channel API endpoint.
Prepare GraphQL queries
Refer to the official GraphQL documentation to learn the general principles of queries.
Xperience generates a GraphQL schema for every headless channel, which includes:
- Query fields and types for all headless content types assigned to the channel.
- Types for all reusable content types that are linked through the fields of the content types included in the schema.
- Unions for any fields of the content types included in the schema that can contain linked items of multiple content types.
- Interfaces for any reusable field schemas assigned to the included content types.
- Scalar types for all data types used by the fields of the included content types.
- Input types with the
FilterandSortersuffixes for all included content types and scalars. - Additional system types, e.g., representing fields containing linked media files, assets or pages.
Custom data types are not available in the GraphQL API for headless channels. Only the built-in scalar types can be used in content types provided through the API. Any custom data types will not be included in the GraphQL schema and cannot be queried via the API.
The schema is automatically updated when you add/remove content types for headless channels or adjust their fields.
Only content retrieval is supported. The schema of headless channels does not include any GraphQL mutations for adding or modifying content.
To inspect the GraphQL schema of a headless channel, access the given channel’s API endpoint, e.g.:
https://example.com/graphql/09114e33-7578-4152-af81-62677bcca740
To learn how to find or configure a headless channel’s API endpoint, see Headless channel management.
There are several ways to explore the GraphQL schema and craft queries:
You need to have the AllowIntrospection option enabled for your application to explore the GraphQL schema.
Introspection – you can query the
__schemafield to retrieve information about the GraphQL schema and see available queries.Banana Cake Pop (now known as Nitro) – a developer IDE that allows you to explore the schema using a graphical user interface, as well as create and run queries to see the results immediately. You can download the desktop app or access the tool in a browser by adding /ui to your Xperience application’s GraphQL endpoint path. The tool’s default URL path is /graphql/ui, but can be customized via the
GraphQlEndpointPathconfiguration key.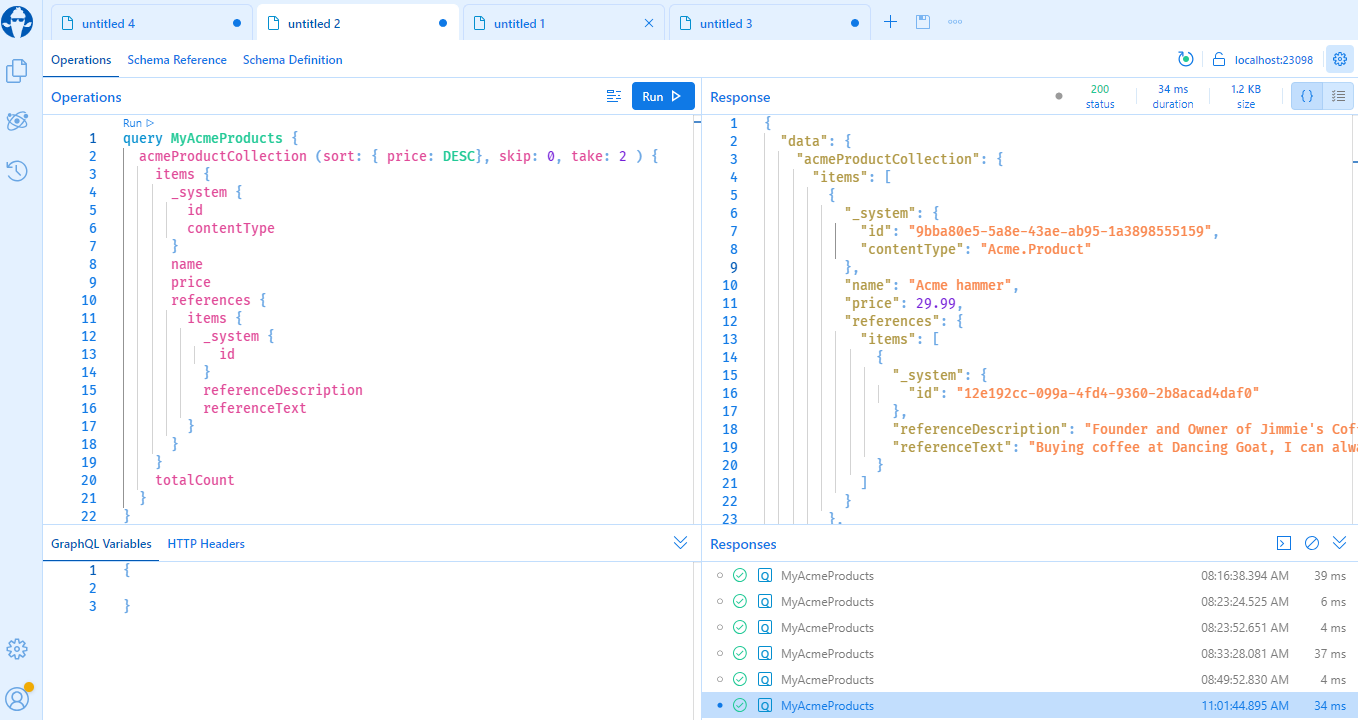
Banana Cake Pop (Nitro) configuration
In the Connection Settings of the IDE, make sure of the following:
- Schema Endpoint is set to the full URL of the channel’s API endpoint.
- Authorization is configured correctly with a valid API key.
Basic querying
The GraphQL schema contains the following query fields and types for each headless content type assigned to the given channel:
|
Query field |
Type |
|
|
|
|
|
|
Individual item types have fields matching the fields of the given content type in Xperience. Each Collection type contains an items sub-field, which allows you to access an array of the retrieved items.
The following query retrieves all headless items of the Acme.Product content type, loading the data in the name and price fields:
{
acmeProductCollection {
items {
name
price
}
}
}
Each item type also has the additional _system field(of the _System type) with general sub-fields like id and contentType.
{
acmeProductCollection {
items {
_system {
id
contentType
}
name
price
}
}
}
To retrieve a specific item, use one of the following approaches:
Query a field storing a collection of items and filter the specific item using the
whereargument.Query a single item field and set the
idargument to the required content item’s GUID. This approach is suitable when you can populate the id argument using data retrieved by a previous query.GraphQL{ acmeProduct(id: "7aa56aa6-1d6f-4a3e-8f54-38e4ee3e4a62") { name price } }
Content restrictions for headless channels
Headless content does not include secured content items that have the Requires authentication flag enabled.
Retrieval of latest or published headless content
Based on your needs, you may want to retrieve headless content in different workflow states. For example, to enable content editors to preview the headless content before they publish it, retrieve the content in its latest edited version. Alternatively, when retrieving headless content for your production environment, you typically want to retrieve only published versions of items.
To choose which version (latest or published) of headless content will be retrieved from Xperience, authenticate your requests with an API key using the corresponding access type.
When retrieving the latest version of headless items, linked items are also retrieved in their latest edited version.
Similarly, when retrieving published items, only published linked items are retrieved.
Languages
When querying item or collection fields, you can control which language variant is returned by setting the following arguments:
languageName– the code name of the language in which you want to retrieve the content item.useLanguageFallbacks– indicates whether the closest language variant available in the fallback chain is retrieved if the item is not available in the requested language.
{
acmeProductCollection(languageName: "es", useLanguageFallbacks: true) {
items {
name
price
}
}
}
Workspaces
When querying item or collection fields, you currently cannot control which workspace the content is retrieved from.
Linked items
Headless items may contain fields that link to other reusable content items or headless items. All linked content types are represented in the GraphQL schema according to the same rules described above, with both single item and collection types. This includes content types that are linked recursively through the fields of other linked types.
When querying deeply nested linked items (e.g., recursively linked content), GraphQL enforces a maximum depth limit. By default, the limit is set to 5. You can customize it via the MaxFieldCycleDepth configuration key.
The following query retrieves headless items of the Acme.Product content type, with additional linked content items stored in the reviews field:
{
acmeProductCollection {
items {
name
price
reviews {
items {
reviewText
reviewStars
}
}
}
}
}
When retrieving items from a field where it is possible to select multiple content types, the items are returned as a GraphQL Union. Unions can be queried using inline fragments to target each content type individually. The following query retrieves headless items of the Acme.Product content type, with the additional linked content items of two content types (Acme.Coffee and Acme.GrinderPage) stored in the productItems field:
query {
acmeProductCollection {
items {
name
productItems {
items {
... on AcmeCoffee {
_system {
contentType
}
coffeeName
coffeeDescription
coffeeTastes {
name
title
}
}
... on AcmeGrinderPage {
_system {
url
contentType
}
grinderPageTitle
grinderPageSummary
grinderPageText
grinderPagePublishDate
}
}
}
}
}
}
Linked pages
There are two options to link to website channel pages in headless channels:
- Page selector fields
- Fields that link to pages using the Page selector form component and the Pages data type in Xperience. Such fields are represented as a
[_WebPage!]array in the GraphQL schema. - The
_WebPagetype exposes theurlfield, which stores the absolute canonical URL of the given page containing the main domain of the related website channel. - You cannot use the
_WebPageobjects to access the fields of the page content type itself. If you wish to associate other data with the linked page, create a reusable content type representing page links with a Pages field for selecting the target page, and additional fields for any required data (e.g., a name or title for the link). - This approach is recommended when you want to link to pages regardless of their content type and only need URLs of the pages, e.g., when building navigation.
- Fields that link to pages using the Page selector form component and the Pages data type in Xperience. Such fields are represented as a
- Combined content selector fields
- Fields that link to pages using the Combined content selector form component and the Page and reusable items data type in Xperience. Such field are represented as a GraphQL Union when selection of multiple content types is allowed. Otherwise, an array of web page objects is used.
- The
_systemfield exposes theurlproperty, which stores the absolute canonical URL of the given page containing the main domain of the related website channel. - Web page objects retrieved from Combined content selector fields expose all fields of the content type itself.
- This approach is recommended when you want to retrieve web page data of certain content types. If you want to retrieve pages of multiple content types, you need to handle each content type individually using inline fragments.
In the following query example, a Navigation item headless content type has a linkedPage field linking to a website channel page using the Page selector. The title is provided by the headless content type.
{
acmeNavigationItemCollection {
items {
navigationItemTitle
linkedPage {
url
}
}
}
}
In the following query example, an Article page content type has a linkedPages field linking to website channel pages using the Combined content selector. The title, summary and content of the article is also retrieved from web pages.
{
acmeArticlePageCollection {
items {
linkedPages {
items {
_system {
url
}
articleTitle
articleSummary
articleText
}
}
}
}
}
Pages linked in rich text fields
If a page is linked within the content of a rich text field in Xperience and this field is queried by the headless API, the returned data contains a link with an absolute canonical URL containing the domain under which the headless channel endpoint was accessed.
Fields referencing reusable field schemas
For content type fields that link to content items of multiple content types via reusable field schemas (using the combined content selector), you can only directly access the properties of the reusable field schema (represented as an interface in the GraphQL schema). To access the properties of the underlying concrete content types, use inline fragments.
{
acmeProductCollection {
items {
name
price
promotions {
items {
productTitle,
productDescription
... on AcmeGrinder {
grinderText
}
}
}
}
}
}
Assets
Content types in Xperience may have fields that store or link to file assets (images, videos, documents, etc.).
- Content item asset fields of reusable content types storing content item assets are represented by the
_ContentItemAssettype in the GraphQL schema.- Note: retrieval of image variants is currently not supported.
- Media files fields of any content type linking to one or more media library files are represented as an
[_Asset!]array in the GraphQL schema.- Note: Media libraries have been sunset and will be removed in the future.
The _ContentItemAsset and _Asset types expose various fields with the file’s metadata. The path field stores the relative URL path, which you can use to link or display the file.
In the following query example, a linked Promotion content type has a promotionTeaserImage asset field.
{
acmeProductCollection {
items {
name
price
promotions {
items {
promotionArticleTitle
promotionTeaserImage {
# Relative URL path to the asset.
path
# Width and height of the asset in pixels. Null for non-image assets.
width
height
}
}
}
}
}
}
Assets linked in rich text fields
If an image or other file is linked within the content of a rich text field in Xperience and this field is queried by the headless API, the returned data contains an absolute file URL containing the domain under which the headless channel endpoint was accessed.
Content item assets in latest versions
Retrieved URLs of content item assets in their latest version, both relative and absolute, are valid only for 10 minutes. If you want to access a content item asset after this limit, you need to retrieve the asset again.
Taxonomies
Content types in Xperience may have fields that store tags related to the content in taxonomy fields.
Taxonomy fields of content types storing tags are represented by the _Tag type in the GraphQL schema. The _Tag type exposes the following properties for each tag:
- name – the code name of the tag.
- title – the display name of the tag.
- description – a brief description of the tag.
In the following query example, a Product content type has a productCategory taxonomy field.
{
acmeProductCollection {
items {
name
price
productCategory {
name
title
description
}
}
}
}
Time fields
The values of Date and time fields (represented by the DateTime scalar type) are always retrieved in the time zone of the server where the application is running. If required, you can convert to a different time zone in the code of your client application.
Smart folder fields
Fields with the Smart folder data type are currently not supported when retrieving content for headless channels.
Filtering
The GraphQL schema automatically includes input types with the Filter suffix for all included content types. These filters allow you to limit which items are returned when you query a *Collection field. Access the filters by adding the where argument to any collection field in your query.
The collection filters have fields matching the fields of the corresponding content type. These filter fields use scalar filter types with sub-fields representing comparison operations suitable for the given data type. For example: contains, eq (equals), nstartsWith (does not start with) for_TextFilter.
Each where argument can only filter over a single scalar field (combined AND/OR filters are not supported).
You can combine filtering with sorting arguments.
{
acmeProductCollection(where: { name: { contains: "hammer"}}) {
items {
name
price
}
}
}
{
acmeProductCollection(where: { price: { gt: 50}}) {
items {
name
price
}
}
}
{
acmeProductCollection {
items {
name
price
reviews(where: { reviewStars: {gte: 3}}) {
items {
reviewText
reviewStars
}
}
}
}
}
You can also filter collections based on taxonomy fields using the following operations:
- containsAny – retrieves items that contain any of the specified tags or contain child tags of any of the specified tags.
- containsAll – retrieves items that contain all of the specified tags or contain child tags of all of the specified tags.
In the following examples, productCategory is a taxonomy field (of type _Tag).
{
acmeProductCollection (where: {productCategory: {containsAny: [ "Electronics", "Tool" ]}}) {
items {
name
price
productCategory {
name
title
description
}
}
}
}
Sorting
The GraphQL schema automatically includes input types with the Sorter suffix for all included content types. These sorters allow you to control the order in which items are returned when you query a *Collection field. Access the sorters by adding the sort argument to any collection field in your query.
The collection sorters have fields matching the fields of the corresponding content type. You can set the sorter fields to either the ASC (ascending) or DESC (descending) values from the _Sorter enum type.
You can combine sorting with filtering arguments.
{
acmeProductCollection(sort: { price: DESC }) {
items {
name
price
}
}
}
Pagination
Pagination allows you to retrieve content items in smaller, more manageable segments. To control pagination, add the following arguments when you query a *Collection field:
skip– the index (0-based) of the item from which the retrieved segment starts. For example, if skip is 5, the segment starts from the 6th item.take– how many items are retrieved in the segment, starting from the index set by skip (or the first item if skip is not specified). The maximum take value is 100.
Every collection type has the totalCount field, which returns the total number of retrieved items regardless of pagination applied by the skip and/or take arguments.
You can combine pagination with sorting and filtering arguments.
{
acmeProductCollection(skip: 0, take: 10) {
items {
name
price
}
totalCount
}
}
Retrieve headless channel content
To retrieve headless channel content from your applications or services, send requests to the API endpoint of the appropriate headless channel, for example:
https://example.com/graphql/09114e33-7578-4152-af81-62677bcca740
To learn how to find or configure a headless channel’s API endpoint, see Headless channel management.
A standard GraphQL POST request has the Content-Type header set to application/json, and includes a JSON-encoded body containing a GraphQL query.
{
'query': ...
}
Authentication
GraphQL API endpoints require all requests to have the Authorization header containing a valid and enabled API key for the given headless channel (see Headless channel management for more information about API keys).
Authorization: Bearer <ApiKey>
Authorizaton header security recommendations
If you set the Authorization header directly when sending requests from a client API on a public web page, it can be seen by anyone. To ensure the security of your API keys, we recommend that you use a backend proxy server to add the Authorization header and forward the requests to the GraphQL API endpoint.
Cross-origin resource sharing
For requests originating from the client-side code of web applications, you need to ensure Cross-Origin Resource Sharing (CORS).
To configure allowed origins:
Open the Settings application in the Xperience administration.
Navigate to the Content → Headless category.
Fill in Allowed origins. You can enter the following values:
- Domain names from which content retrieval requests will be sent, separated by semicolons. For example: www.example.com;sampleapp.net
- The * wildcard, which means that headless API endpoints can be accessed by any origin. Some system configurations may not accept responses that allow all origins.
Select Save.
Headless API endpoints now accept requests from the specified domains.
If you wish to configure different allowed origins for specific application environments (local development, QA, production, etc.), you can use the CMSHeadless:CorsAllowedOrigins key in your application’s configuration file (appsettings.json by default) or the HeadlessOptions.CorsAllowedOrigins option in your project’s startup file (Program.cs). See Headless channel management to learn more about configuring the headless API. However, keep in mind that the Allowed origins setting in Xperience overrides CORS allowed origin values set in your application’s configuration file or startup options.
Additionally, the CorsAllowedHeaders key or option allows you to restrict which HTTP headers are allowed for headless content retrieval requests (in addition to CORS-safelisted request headers). Separate the HTTP header names using semicolons. If not set, all headers are allowed by default.
{
...
"CMSHeadless": {
"CorsAllowedOrigins" : "www.example.com;sampleapp.net",
"CorsAllowedHeaders": "Authorization;Cache-Control"
...
}
}
When you send a request from a web application to a different domain, the user agent automatically includes the Origin HTTP header. If the domain name of the origin is allowed by your configuration, Xperience returns a response with the Access-Control-Allow-Origin header (set to either the origin domain or the * wildcard). The request is successful and the consuming application receives the requested data in the response’s payload.
If you do not set any allowed origins, headless API endpoints do not include the Access-Control-Allow-Origin header in responses, which may lead to failed requests. You can use an empty value if you wish to handle HTTP headers manually.
When sending responses to Preflight requests, the system includes the Access-Control-Allow-Headers header with a value containing the header names specified in the CorsAllowedHeaders option, or all header names sent in Access-Control-Request-Headers if the option is not set.