
ContentRetriever API
IContentRetriever provides a unified API to fetch various types of content managed by Xperience from within web applications. It’s intended as the primary service for the retrieval of:
- Pages
- Reusable content items
- Content sharing reusable field schemas
The simplest way to use IContentRetriever is directly calling each method with the default settings, which are optimized for most common scenarios:
// Retrieve the current page
var currentPage = await contentRetriever.RetrieveCurrentPage<HomePage>();
// Retrieve all pages of a specific content type
var articles = await contentRetriever.RetrievePages<ArticlePage>();
// Retrieve content items by content type
var testimonials = await contentRetriever.RetrieveContent<TestimonialItem>();
Functionally, the API serves as an abstraction layer over content query, where it handles common retrieval scenarios by providing default, recommended configuration for various aspects like query construction, language fallback handling, and linked item retrieval. However, it also provides developers the option to override these defaults by exposing parts of the retrieval lifecycle (e.g., query construction, model mapping) via function delegates.
This page introduces concepts shared by all methods available on the service, together with relevant examples. For a complete method reference, see Reference - ContentRetriever API.
Shared aspects of the API
Configurable retrieval behavior
IContentRetriever method overloads accept an optional parameter object, named according to the retrieval scenario (e.g., RetrieveCurrentPageParameters, RetrievePagesParameters ). These objects allow you to configure the high-level behavior and scope of the content retrieval operation. They primarily control how and under what context data is fetched.
These parameters objects define behavior such as:
- The desired content language (
LanguageName,UseLanguageFallbacks). - Whether to retrieve preview or live content (
IsForPreview). - The depth of linked content to include (
LinkedItemsMaxLevel). - Whether to include content items requiring authentication (
IncludeSecuredItems). - Scope limitations like specific content tree paths (
PathMatch) or workspaces (WorkspaceNames).
When you call a retriever method without providing a specific parameters object – often by using the simpler extension method overloads – or if you provide a default instance (new RetrieveCurrentPageParameters() for example), the API uses sensible defaults.
These defaults are designed for the most common use cases, typically relying on the current request’s context (e.g., using the detected preferred language, respecting the current preview mode status) and opting for safer, less resource-intensive settings (like LinkedItemsMaxLevel = 0 and IncludeSecuredItems = false). This results in concise and performant queries.
The flexibility of this approach is in overriding the defaults when instantiating these objects. This allows you to tailor the retrieval to specific requirements. For example:
- You might need to display content in a specific language regardless of the user’s preference:
new RetrievePagesParameters { LanguageName = "spanish" } - You might need to fetch related items linked from a main article:
new RetrieveCurrentPageParameters { LinkedItemsMaxLevel = 1 } - You might need to ensure you’re always getting the latest, unpublished content:
new RetrieveContentParameters { IsForPreview = true } - You might need to retrieve pages only within a specific section of the site:
new RetrievePagesParameters { PathMatch = PathMatch.Children("/products") }
By using these parameters objects, you gain explicit control over the retrieval context and scope, ensuring the retriever fetches the right content based on your application’s requirements, rather than just relying on provided defaults.
All *Parameters objects also include a Default property. This property provides a default instance of the specific parameter type when no custom configuration is needed. Useful when a configuration action is syntactically required but no additional configuration is necessary (for instance, when using certain advanced overloads of the available methods). However, note that the default object is only populated in certain scenarios, see: Request context requirements.
Optional query configuration
Certain overloads of IContentRetriever methods accept an additionalQueryConfiguration parameter. This parameter allows you to directly configure the underlying content query builder instance, providing advanced control over the database query construction beyond what is possible using the retrieval parameters described above.
You can use this to apply various query modifications, such as:
Filtering – limiting results using Where conditions.
Sorting – defining OrderBy clauses.
Projection – specifying exact database columns to retrieve using Columns.
Security considerations
Column expressions inColumns,OrderBy, and the left-hand column operands inWheremethods are not parameterized against SQL injection. Only use trusted, developer-controlled values. If these values originate from external input, validate them against an allowlist. See Protect against SQL injection (the principles described for the ObjectQuery API apply).Paging – limits results using:
- TopN – returns only the first
Nrecords according to the specified order. Cannot be combined withOffset. - Offset – skips the first
offsetrecords and then retrieves the nextfetchrecords. This is the recommended method for implementing paging and requires anOrderByclause to ensure consistent results. Cannot be combined withTopN.
- TopN – returns only the first
Linked items configuration – options for retrieving linked items via WithLinkedItems. Linked item depth is reflected from the corresponding method configuration object.
Method-specific options – certain configuration options are unique to specific methods. For example,
UrlPathColumnsfor page queries or InSmartFolder for content item queries.
Query configuration objects are named according to the corresponding retrieval method (e.g., RetrieveCurrentPageQueryParameters, RetrievePagesQueryParameters, RetrieveContentQueryParameters). All *QueryParameters objects also include a Default property. This property provides a default instance of the specific parameter type when no custom configuration is needed. Useful when a configuration action is syntactically required but no additional configuration is necessary (for instance, when using certain advanced overloads of the available methods).
URL retrieval behavior
When retrieving pages using IContentRetriever, you have control over how page URLs are generated, particularly for multilingual sites and when retrieving data explicitly to construct URLs. This is managed through the additionalQueryConfiguration delegate, which allows you to customize the underlying query.
Controlling URL language with fallbacks
By default, IContentRetriever methods configure their internal queries to use UrlLanguageBehavior.UseRequestedLanguage. When a page uses content from a fallback language, the URL is still generated for the originally requested language.
Use SetUrlLanguageBehavior(UrlLanguageBehavior.UseFallbackLanguage) to generate URLs that match the actual language of the retrieved content instead of the requested language.
var pages = await contentRetriever.RetrievePages<ArticlePage>(
new RetrievePagesParameters { LanguageName = "es" },
query => query.SetUrlLanguageBehavior(UrlLanguageBehavior.UseFallbackLanguage),
new RetrievalCacheSettings(cacheItemNameSuffix:
$"{nameof(RetrievePagesQueryParameters.SetUrlLanguageBehavior)}|UseFallbackLanguage")
);
foreach (var page in pages) {
// If content fell back to English, URL will be
// '/en/my-page' instead of '/es/my-page'
var url = page.GetUrl();
}
Optimizing retrieved data for URL generation
To improve query performance when your primary need is page URLs rather than full page content, use the UrlPathColumns() method in the additionalQueryConfiguration.
This method ensures that the query only fetches the minimal set of data columns required to construct page URLs. This is especially beneficial when you intend to use the URLs for navigation menus, sitemaps, or other linking purposes without loading the entire page object.
var pagesWithUrlsOnly = await contentRetriever.RetrievePages<ArticlePage>(
RetrievePagesParameters.Default,
// Retrieves the title and all columns required for URL resolution
query => query
.Columns("ArticleTitle")
.UrlPathColumns(),
new RetrievalCacheSettings(cacheItemNameSuffix:
$"{nameof(RetrievePagesQueryParameters.Columns)}|ArticleTitle|{nameof(RetrievePagesQueryParameters.UrlPathColumns)}")
);
Using UrlPathColumns() helps ensure that GetUrl() can operate on the retrieved objects without further database calls, as the necessary data is already pre-fetched.
Implicit result caching
The IContentRetriever API supports implicit result caching. By default, caching is enabled for all retrieval methods unless explicitly disabled using RetrievalCacheSettings.CacheDisabled.
You can configure caching behavior using the RetrievalCacheSettings parameter. This parameter allows you to:
- Enable or disable caching – Use
RetrievalCacheSettings.CacheDisabledto disable caching for specific retrieval operations. - Set cache item name suffix – If you modify the default query used when retrieving data, you must ensure a unique cache item name for the data via a suffix appended to the cache key. See Ensure unique cache keys.
- Set cache expiration – Specify the cache expiration time using the
CacheExpirationproperty. - Use sliding expiration – Enable sliding expiration by setting
UseSlidingExpirationtotrue. - Add additional cache dependencies – Use the
AdditionalCacheDependenciesproperty to define custom dependencies for cache invalidation.
Default cache settings
- The default cache expiration time is set to 10 minutes. This value is used when no specific expiration is provided in
RetrievalCacheSettings. You can set a default expiration time globally for all requests made via the content retriever API usingContentRetrieverCacheOptions. See Set global cache expiration time. - Sliding expiration is disabled by default, meaning the cache duration is fixed and doesn’t get extended when the cached item is accessed.
Caching with custom configuration
// Configure cache settings with a 30-minute expiration and sliding expiration enabled.
var cacheSettings = new RetrievalCacheSettings(
// Add a unique suffix to identify the cached data.
cacheItemNameSuffix: $"{nameof(ContentTypesQueryParameters.OfContentType)}|ArticleGenerated",
// Cache entries will expire 30 minutes after their last access.
cacheExpiration: TimeSpan.FromMinutes(30),
// Resets the expiration timer on each access to keep frequently accessed items in the cache.
useSlidingExpiration: true);
var result = await contentRetriever.RetrieveCurrentPage<ArticleGenerated>(
RetrieveCurrentPageParameters.Default,
RetrieveCurrentPageQueryParameters.Default,
cacheSettings
);
Disable result caching
var result = await contentRetriever.RetrieveCurrentPage<ArticleGenerated>(
RetrieveCurrentPageParameters.Default,
RetrieveCurrentPageQueryParameters.Default,
// Disables result caching for the query
RetrievalCacheSettings.CacheDisabled
);
Ensure unique cache keys
When you use the additionalQueryConfiguration parameter to customize the query, you must provide a cacheItemNameSuffix in RetrievalCacheSettings. This suffix ensures that the cache key is unique for your specific query variation, as the system does not reflect the additional query configuration in the final constructed cache item name.
A recommended pattern for the suffix is to combine the name of the query configuration object with a string representation of its parameters. For example:
var cacheSettings = new RetrievalCacheSettings(
// Constructs a unique suffix by combining the string representation of the parameter values.
// This ensures that different query configurations result in different cache keys.
cacheItemNameSuffix: $"{nameof(RetrievePagesQueryParameters.TopN)}|3"
);
var result = await contentRetriever.RetrieveCurrentPage<ArticleGenerated>(
RetrieveCurrentPageParameters.Default,
a => a.TopN(3),
cacheSettings
);
This practice helps prevent cache collisions when different query configurations might otherwise produce the same default cache key. Your strategy for generating suffixes should ensure consistent outputs varied only by the provided parameterization. This way, you leverage the cache item name generated internally by the method to its maximum potential and minimize the possibility of caching identical results multiple times under different keys.
In requests that don’t modify the retrieval query in any way, the suffix can be defined as an empty string.
Set global cache expiration time
Results returned by the API are by default cached for 10 minutes, unless overridden directly at the point of the retrieval operation by a specific instance of RetrievalCacheSettings. You can set this default caching period using ContentRetrieverCacheOptions and the options pattern.
// Sets the global default cache expiration for IContentRetriever instances.
// This value is used if no specific RetrievalCacheSettings.CacheExpiration is provided
// at the point of a retrieval operation, allowing for both global defaults and granular overrides.
builder.Services.Configure<ContentRetrieverCacheOptions>(options =>
{
// Sets the default cache duration to 30 minutes.
// Individual IContentRetriever calls can override this via RetrievalCacheSettings.
options.DefaultCacheExpiration = TimeSpan.FromMinutes(30);
});
Gather generated cache dependencies
The IContentRetriever API automatically collects generated cache dependencies for all retrieved items. This is achieved using the CacheDependencyCollector class, which operates in a scoped context. You can access the collected dependencies by creating an instance of CacheDependencyCollector and calling its GetCacheDependency() method.
This is particularly useful when you have a broader caching strategy that needs to incorporate the dependencies of data fetched by multiple content retriever calls. For example, you can disable caching for individual requests, collect cache dependencies generated for the retrieved data, and use them as dependencies in a broader cached section.
using Kentico.Content.Web.Mvc;
using CMS.Helpers;
// Initializes a new collector scope
using (var dependencyCollector = new CacheDependencyCollector())
{
var cachedData = await progressiveCache.LoadAsync(async (cs) =>
{
var page = await contentRetriever.RetrieveCurrentPage<Home>(
RetrieveCurrentPageParameters.Default,
RetrieveCurrentPageQueryParameters.Default,
// Cache disabled for the request
cacheSettings: RetrievalCacheSettings.CacheDisabled
);
var relatedArticles = await contentRetriever.RetrievePages<ArticlePage>(
RetrievePagesParameters.Default,
RetrievePagesQueryParameters.Default,
// Cache disabled for the request
cacheSettings: RetrievalCacheSettings.CacheDisabled
);
// Get the combined dependencies from all IContentRetriever calls
// within the CacheDependencyCollector's scope up until this point.
// The current set of dependencies continues to accumulate
// until the parent scope gets disposed.
cs.CacheDependency = dependencyCollector.GetCacheDependency();
// ...
}, cacheSettings);
}
The collector also supports nested scopes. If you create multiple CacheDependencyCollector instances in a nested fashion (e.g., within a method that calls another method, both using a collector), dependencies from inner scopes are automatically propagated to outer scopes upon disposal of the inner collector.
The CacheDependencyCollector.AddCacheDependency(CMSCacheDependency dependency) method can also be used to manually add dependencies to the current scope if needed. Note that the method must be called from inside an initialized collector scope – the call otherwise returns an exception.
Request context requirements
Certain IContentRetriever method parameters (ChannelName, LanguageName, IsForPreview) can be detected automatically when the request’s domain matches a configured website channel.
// Callable from any route where request domain
// matches an existing website channel domain.
var articles = await contentRetriever.RetrievePages<ArticlePage>();
Additionally, the RetrieveCurrentPage method is only intended to be called from inside code handled by content tree-based routing, which provides all required parameters for the retrieval (page ID, etc.).
// Callable from code handled by content tree-based routing.
var currentPage = await contentRetriever.RetrieveCurrentPage<HomePage>();
When automatic detection is not possible, you need to provide these parameters explicitly:
var articles = await contentRetriever.RetrievePages<ArticlePage>(
new RetrievePagesParameters
{
ChannelName = "MyWebsite",
LanguageName = "en",
IsForPreview = false
}
);
Explicit parameterization is needed when:
- Request domain does not match any configured website channel.
- Executing code in background jobs or scheduled tasks.
- Running code in console applications or CLI tools.
If context cannot be detected automatically, the API throws an InvalidOperationException with messages such as:
- “The HTTP context is not available. Ensure that the
IContentRetrieverWebsiteContextProvideris used within a valid HTTP request context.” - “Website data context could not be retrieved. Parameters
ChannelName,LanguageName, andIsForPreviewneed to be specified manually.”
Custom model mapping
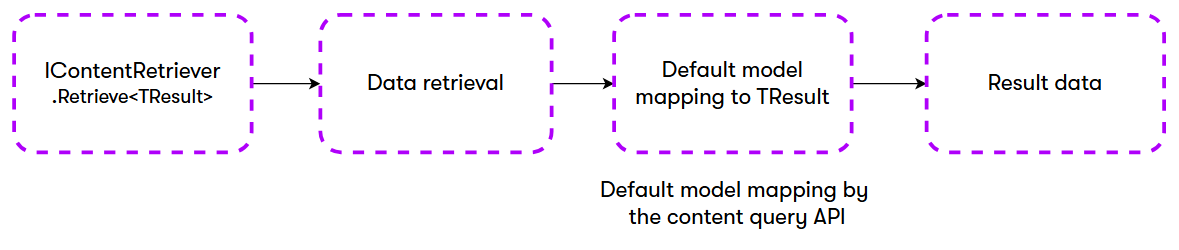
The IContentRetriever API provides flexible model mapping capabilities that support both registered content types and custom model classes. The underlying model mapping system uses the following priority:
Registered content types – If a model type is registered for the content type via RegisterContentTypeMappingAttribute and your target model type (provided via the generic method parameter) is assignable from the registered type, the registered type is used for mapping.
Direct model mapping – If no registered type is found or it’s not assignable, your specified model type is used directly for mapping. The model must be a non-abstract class, struct, or record with a parameterless constructor. The API attempts automatic mapping to your specified model, using case-insensitive property matching with the columns retrieved by the query. This flexibility allows you to use any custom, simplified models containing only the properties you need.
Custom mapping with configureModel delegate
Additionally, IContentRetriever method overloads include an optional configureModel parameter, which allows you to inject custom logic into the model mapping pipeline for even more advanced scenarios.
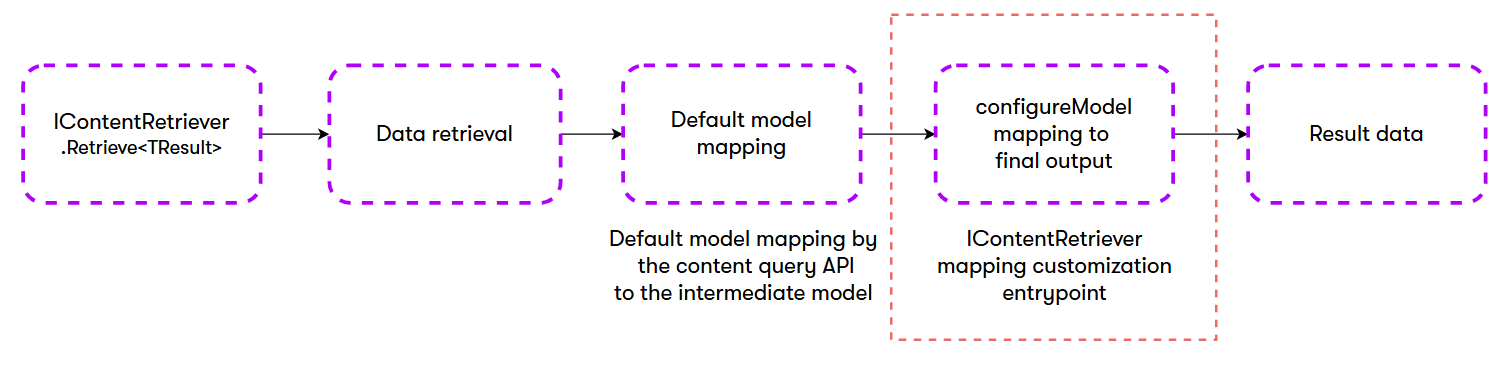
The parameter has the following signature:
Func<IContentQueryDataContainer, TInput, Task<TResult>> configureModel;
This parameter gives you control over how the retrieved data is mapped to your resulting model class.
IContentQueryDataContainer– contains the database row (page, content item) being mapped. You can access column values viaGetValue<TValue>(string columnName).TInput– the intermediate mapped object. This could be either a registered content type model or your custom model type, depending on the mapping priority. For example, when calling:contentRetriever.RetrievePages<ArticleGenerated>()TInputcontains an instance ofArticleGeneratedfor each mapped item from the result set. You can use this intermediate representation to fetch the data, run additional transformations (combining fields, or enriching the model with external data) and any other custom logic.TResult– the final type you want to return from the content retrieval operation. This is the type of object that yourconfigureModeldelegate creates and returns.
See the Run queries and map the result documentation to learn about the content item query model mapping lifecycle. IContentRetriever methods simply expose certain parts of the lifecycle.
Direct model mapping without registration
You can use any custom model class directly without needing to register it using RegisterContentTypeMappingAttribute. If you leave configureModel as null, the content retriever attempts automatic mapping to your specified model type, using case-insensitive property matching with the columns retrieved by the query. This works for both generated model classes and custom classes that match the underlying content type structure.
// Custom model class without content type registration
public class SimpleArticle
{
public string Title { get; set; }
public string Summary { get; set; }
public DateTime PublishedDate { get; set; }
}
var contentTypes = new[] { ArticlePage.CONTENT_TYPE_NAME, BlogPage.CONTENT_TYPE_NAME };
// Direct mapping to custom model 'SimpleArticle' that does not need to be registered
var articles = await contentRetriever.RetrievePagesOfContentTypes<SimpleArticle>(contentTypes);
// 'ArticleGenerated' is a model class generated by Xperience
// Works the same way as before - uses registered mapping if available
var articles = await contentRetriever.RetrievePages<ArticleGenerated>();
Advanced mapping with configureModel delegate
For more complex scenarios, you can provide a custom mapping function using the configureModel delegate. This function receives the raw data for each retrieved item and the intermediate mapped object, allowing you to implement custom transformation logic.
using Kentico.Content.Web.Mvc;
// Custom view model for complex transformations
public class CustomArticleViewModel
{
public string PageTitle { get; set; }
public string PageAdminTitle { get; set; }
public string FormattedDate { get; set; }
}
// Using configureModel for complex transformations
// TInput could be either a registered model or custom model based on mapping priority
var customViewModels =
await contentRetriever.RetrievePages<SimpleArticle, CustomArticleViewModel>(
new RetrievePagesParameters(),
null, // No query modifications
RetrievalCacheSettings.CacheDisabled,
// configureModel delegate for custom transformations
async (container, mappedResult) =>
{
// 'mappedResult' is the intermediate SimpleArticle object
// 'container' provides access to raw database data
return new CustomArticleViewModel
{
PageTitle = mappedResult.Title ?? "Default Title",
PageAdminTitle = container.GetValue<string>("WebPageItemName"),
FormattedDate = mappedResult.PublishedDate.ToString("MMM dd, yyyy")
};
}
);
See Usage scenarios for common use cases and recommendations for when to use either approach.
This mechanism offers flexibility, allowing simple mapping for standard cases and complex, custom transformations for advanced scenarios.
Usage scenarios
Direct mapping to custom models
- Use case: Using custom model classes without requiring content type registration. Create simplified models with only the properties you need, or use models that don’t exactly match the content type structure.
- Approach: Use methods like
contentRetriever.RetrieveCurrentPage<YourCustomClass>()directly. The model must be a non-abstract class with a parameterless constructor.
Simple direct mapping to registered models
- Use case: Retrieving content directly into generated model classes or other registered content type models when your class structure matches the content type fields.
- Approach: Use methods like
contentRetriever.RetrieveCurrentPage<YourRegisteredClass>().
Small adjustments or conformance to shared models (Minimal custom mapping)
- Use case: Making small changes like formatting dates, providing default values, renaming properties for view models, or when the intermediate mapped object needs slight modifications.
- Approach: Use the
configureModeldelegate with simple transformations or object-to-object mapping.
Complex transformations and custom view models (Extensive custom mapping)
- Use case: Transforming fetched content into view models with significantly different structures, combining multiple source fields, performing calculations or conditional logic, or accessing data not directly available through standard mapping.
- Approach: Leverage the
configureModeldelegate extensively to build your target C# object with full control over the transformation process.
Using shared types for bulk content retrieval
Generated model classes implement shared interfaces that provide access to system properties:
- Page content type model classes implement
IWebPageFieldsSource - Reusable content type model classes implement
IContentItemFieldsSource
However, the way IContentRetriever methods work with these interfaces depends on how content types are identified and resolved during retrieval operations.
The following IContentRetriever methods:
RetrievePagesRetrievePagesByGuidsRetrieveContentRetrieveContentByGuids
determine the target content type from the provided generic. This identification happens through the RegisterContentTypeMappingAttribute present on generated model classes.
Since IWebPageFieldsSource and IContentItemFieldsSource are shared interfaces without specific content type mappings, using them directly as generic type parameters is not supported by these methods. The system cannot determine which specific content type to retrieve:
// These approaches are not supported - no content type can be determined
var pages = await contentRetriever.RetrievePages<IWebPageFieldsSource>();
var content = await contentRetriever.RetrieveContent<IContentItemFieldsSource>();
Multi-content type page retrieval with RetrieveAllPages
When you need to retrieve pages across multiple content types without knowing the specific types at compile time, use the RetrieveAllPages method. This method retrieves all web pages that match the specified parameterization:
// Retrieves all page content types matching the specified criteria
IEnumerable<IWebPageFieldsSource> allPages =
await contentRetriever.RetrieveAllPages<IWebPageFieldsSource>(
new RetrieveAllPagesParameters
{
LanguageName = "en-US",
PathMatch = PathMatch.Children("/articles")
}
);
Retrieving pages by GUIDs across content types
When you need to retrieve pages of any content type by specific GUIDs, use the RetrieveAllPagesByGuids method:
// A collection of page GUIDs (typically obtained from Page selector)
var webPageItemGuids = new[] { guid1, guid2, guid3 };
var pagesByGuids = await contentRetriever.
RetrieveAllPagesByGuids<IWebPageFieldsSource>(
webPageItemGuids);
This method provides automatic cache dependency management based on the provided GUIDs, making it more efficient and convenient than manual query configuration.
Limitations for reusable content items
The RetrieveAllPages (RetrieveAllPagesByGuids) approach is only available for page content types. For reusable content items, you must use one of the following approaches:
- Specify exact content types you want to retrieve.
- Use reusable field schemas to group related content types that share common properties.
You can cast results to the shared IContentItemFieldsSource interface when retrieving across multiple reusable field schemas or content types:
// Retrieve a specific reusable content type
var testimonials = await contentRetriever.RetrieveContent<TestimonialItem>();
// Retrieve multiple specific content types using reusable field schema
var schemaNames = new[] { IMetadataFields.REUSABLE_FIELD_SCHEMA_NAME };
IEnumerable<IMetadataFields> itemsWithSchema =
await contentRetriever.RetrieveContentOfReusableSchemas<IMetadataFields>(schemaNames);
// Retrieve across multiple reusable schemas and cast to shared interface
var schemaNames = new[] {
IMetadataFields.REUSABLE_FIELD_SCHEMA_NAME,
ISeoFields.REUSABLE_FIELD_SCHEMA_NAME
};
IEnumerable<IContentItemFieldsSource> itemsWithSchemas =
await contentRetriever.RetrieveContentOfReusableSchemas<IContentItemFieldsSource>(schemaNames);
Method reference
See Reference - ContentRetriever API for a reference of all methods available on IContentRetriever.