
Module: Content modeling guide
20 of 28 Pages
Design atomic content models
Deliver multi-channel experience with atomic content model
The atomic content model breaks content into small, reusable elements – titles and summaries, images, features, benefits, or call to actions that you can link and compose into larger semantic types like Product, Article, or Event.
Store data in reusable content types
Instead of duplicating content across different channels, editors store it once in reusable content types that they can reassemble wherever needed. This keeps the structured data without any presentation information and makes it easy to maintain.
Keep digital content channel-neutral
This atomic approach keeps your content channel-neutral. The same structured product data can appear consistently across your website, email campaigns, headless applications, mobile apps, or any future channels you adopt.
Editors don’t need to rewrite or duplicate content when expanding to a new channel. Instead, they can refer to the same reusable data and present it with the appropriate channel context.
Simplify content management workflow across teams
Working with reusable content gives editors other advantages. They manage their reusable content in the Content hub and layer on channel-specific context using dedicated, channel-specific content types that we refer to as channel-specific wrappers for website pages, headless channel or emails.
Content becomes a single source of truth for reusable content
Different departments can deliver consistent customer experiences across channels through single-source-of-truth management and ensure fast and reliable updates. Each team can manage different parts of the content or its fragments if the project requires it. Teams maintain clear ownership over their data, and the atomic content model helps the company simplify content workflows and approvals across the organization.
Atomic data allows your team to grow
The atomic content model makes the content ready for future expansion. The company’s content operation will not require a full re-architecture each time it adds a new channel or introduces a new marketing touch point. The data structure remains flexible and supports editors, marketers, and developers in delivering personalized and scalable digital experiences.
Compare atomic content modeling with traditional approaches
In traditional content models, teams often use large, single-purpose content types, like a Product page, that contain title, descriptions, images, benefits, CTAs, Open Graph, or SEO metadata within a single item. The page-based approach can feel intuitive and straightforward, especially for single-channel, website-driven experiences.
The traditional approach stores data in pages, which ties the content to a specific presentation layer, most commonly a website.
While this approach can be easy to start with, it can slow down delivering marketing projects as the project grows and the team adds more channels, changes how they manage content, or introduces new ways they need to display data. In the extreme case of page-based content model with all content in Page Builder widgets, they will need more time to update or remove outdated content as editors need to find and update each page where similar or the same content piece appears.
See how atomic content modeling works in practice
Let’s look at an example from the Kbank Business Banking demo site. Suppose you have a Product content type illustrated in the following diagram.
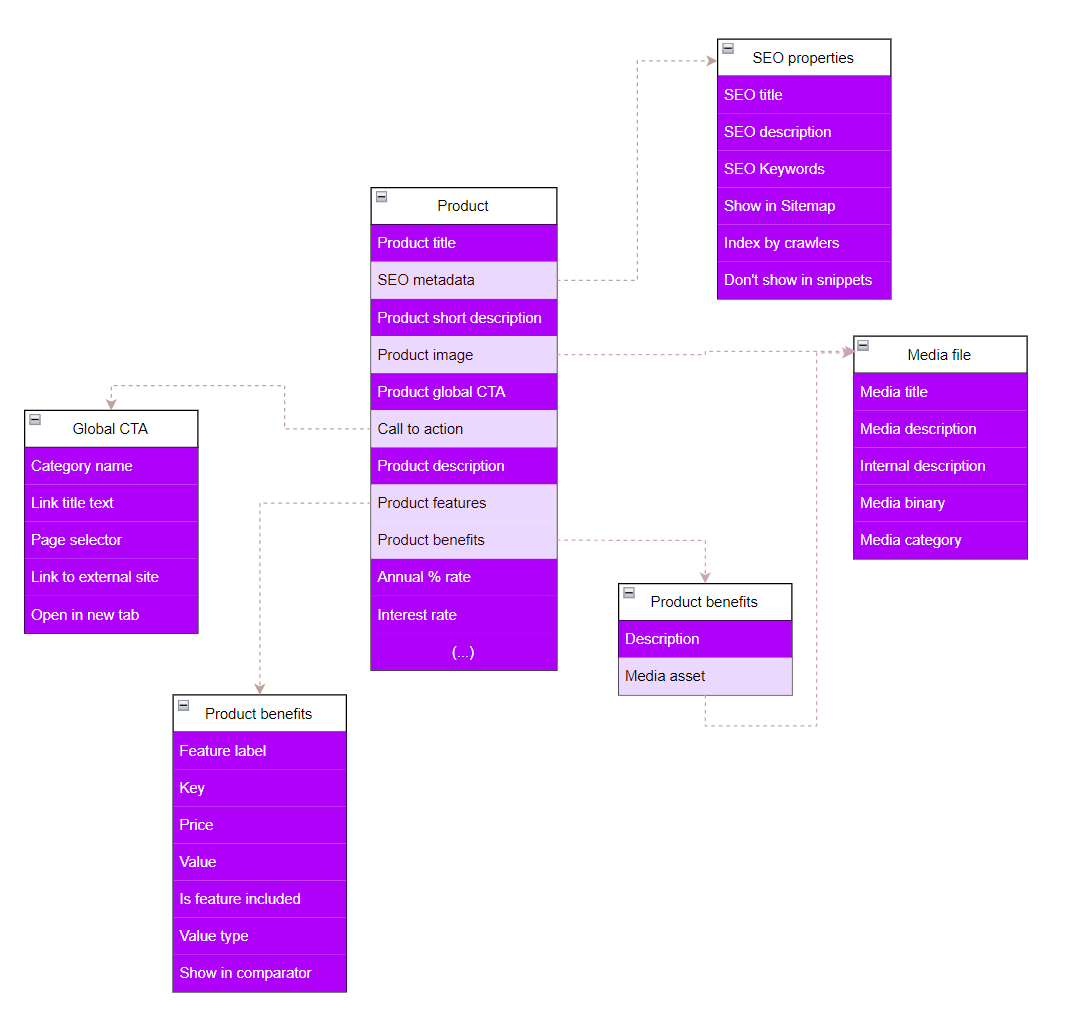
The Product includes a Core schema fields, such as Title, Description, Product summary, and some basic taxonomy. In page-based content model, you might have stored everything else besides the Core content schema into the Product page, as the data describes the product and its capabilities. In the atomic content model, instead of storing everything in one place, you can split related information into separate content types:
- Core product data in reusable field schema
- Product features – built with Product features content type, that contain fields, such as label, key, price, or whether this feature item should be displayed in product comparator component.
- Product benefits – built with Benefits content type that contain description fields and a reference to media file content item.
- Product images – Media file content type, with fields such as title, description or category).
See other examples of semantic content types you can use to translate content objects into a predictable structure.
Use linked items to keep your content reusable
Each of these smaller content types stores reusable information. So if two products share the benefit of Fast access to funds, editors don’t duplicate the information. Instead, they link the benefit to the products.
This gives them the power to reuse content, not duplicate it. When an editor updates the benefit’s description or icon in a content item, all products (or Page Builder widgets) referencing it get the update automatically. Developers can query these linked items in custom code to retrieve collections of references, display the data through widgets, or pull additional data like Call to actions to accompany these benefits.
Approach every content type like a Media asset
Images and other assets, such as videos, infographics, or podcasts, are expensive to create, and it’s natural that businesses want to reuse them as much as possible.
This makes assets the ultimate example of content reusability that you store in the Content hub. Editors refer to content item assets, images, or documents to display them in pages, emails, or headless content. You can find more information about building dedicated content types in material about storing files.
Break content into dedicated reusable pieces and have editors refer to a single item to improve content governance. Identify which pieces of content can be stored into smaller content items or combined into content fragments that convey a semantic meaning, such as a collection of FAQ elements, product features, benefits, testimonials provided by similar-size customers and other content that editors will want to share in the same combination across different channels, or content items that you want to feature together, e.g., in a slideshow.Linked items make it easier to govern who can edit what. For example, your financial services team can manage benefits, while the product team focuses on product specs.
Leverage the combined content selector
Reusing content items improves content maintenance. When an editor updates the referenced item, the content changes are automatically promoted to every other item that uses this content, making content management a breeze. When defining the content model, discuss which types can be reused and create them accordingly.
Editors will use the content item with the Combined content selector form component to ensure reusability. The ContentRetriever API allows developers to query the linked items in their custom code and return a collection of references to content items, which they can further process. For example, they can retrieve URLs of web pages to which editors want to guide their audience. You can also configure the Combined content selector to specify which content types editors can refer to. Specifying allowed content types creates predictable structures and improves the editing and development experience.
Track and manage language variants of content
Atomic content model in Xperience supports multilingual delivery. It allows editors to store reusable content items in one language and track which language variants exist or are missing.
When editors create a language variant of their content, Xperience indicates whether all other content items that compose this content item are translated or not. Xperience shows a yellow border around the untranslated content with a warning icon as you can see in the following image.
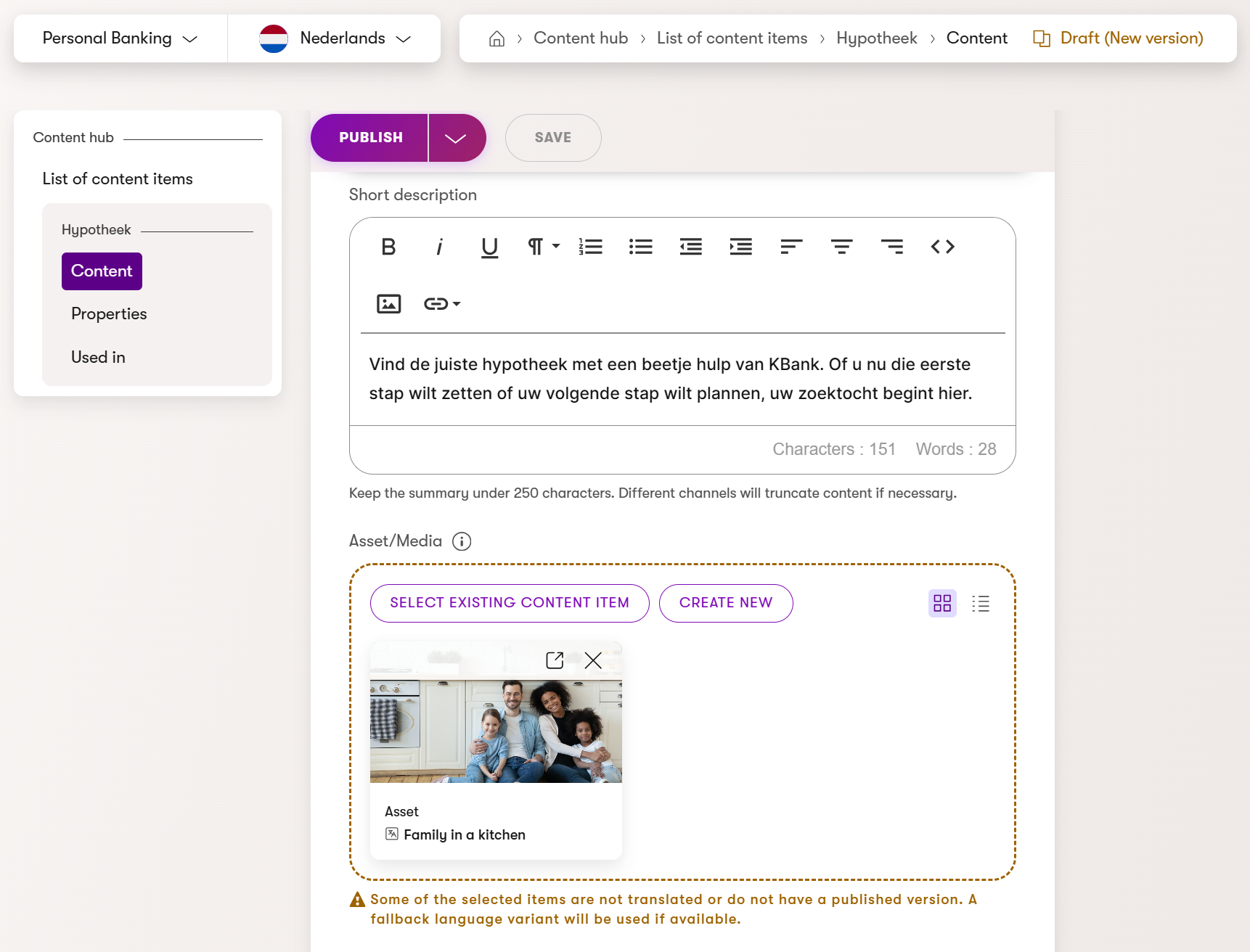
Language fallback allows shared content to remain consistent across languages: Editors don’t need to duplicate it, which reduces translation workload.
Teams can choose which linked items, such as local-specific CTAs or product descriptions that depend on the market variants, should be translated while leaving others, like globally defined disclaimers, taxonomies, or brand visuals, shared across all language versions. This simplifies managing multilingual sites and helps content stay consistent across markets.
Use wrappers to display atomic content across multiple channels
The atomic content model keeps the data clean of channel-specific details. To deliver the reusable content in a specific channel, editors will add necessary channel-specific context by using wrapper pages for headless or website delivery.
A wrapper is a content item (webpage content type in website channels or* headless content type). Editors use wrappers to refer to a specific item in the Content hub* to get global, universal data, for example, for a product, and then layer on the details needed for a specific channel, such as your website, email campaigns, or a headless application. Adding the wrapper page into the content tree also ensures the content can be navigable through a page URL.
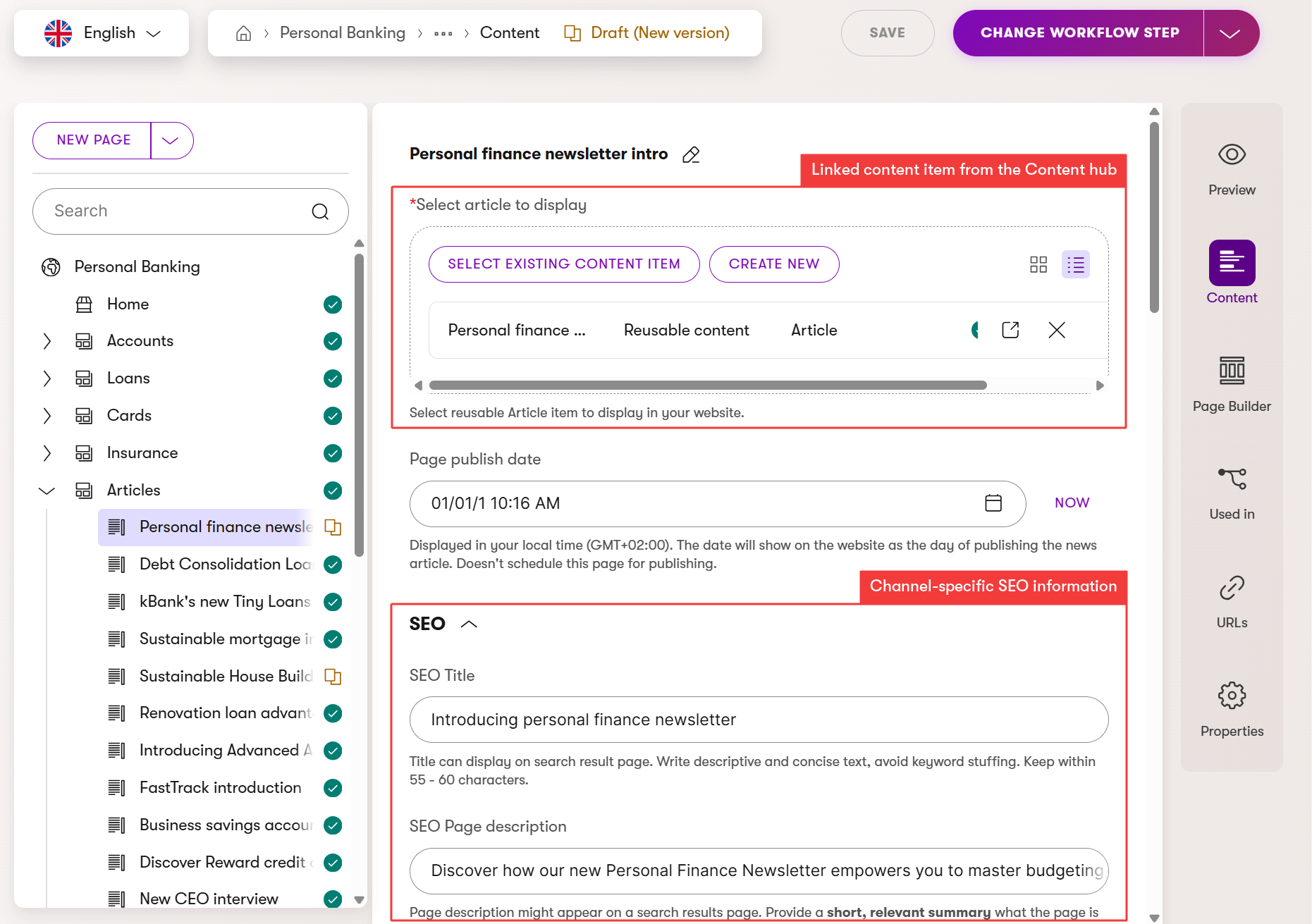
The wrapper page can be as simple as the one shown in the image above. It contains Combined content selector where editors select a reusable product for this page (configured to accept different product content types), and field to override default publishing date, and a SEO reusable field schema.
How page wrappers work on websites
For example, when displaying a product on your website, editors don’t store Open Graph metadata, SEO metadata, canonical URL, or the page publish date inside the Product content type. Instead, they:
- Put a reusable Product content item with valid data for any presentation layer to the Content hub.
- Use a dedicated wrapper page to add a Product page in the website’s content tree.
- Refer to the Product content item stored in the Content hub using a selector.
- Add channel-specific fields in the page wrapper, such as:
- Open Graph title and description for social sharing.
- SEO title and meta description for search engines.
- Publish date and author for blog-like content.
- Channel-specific hero images or banners used only for website channels.
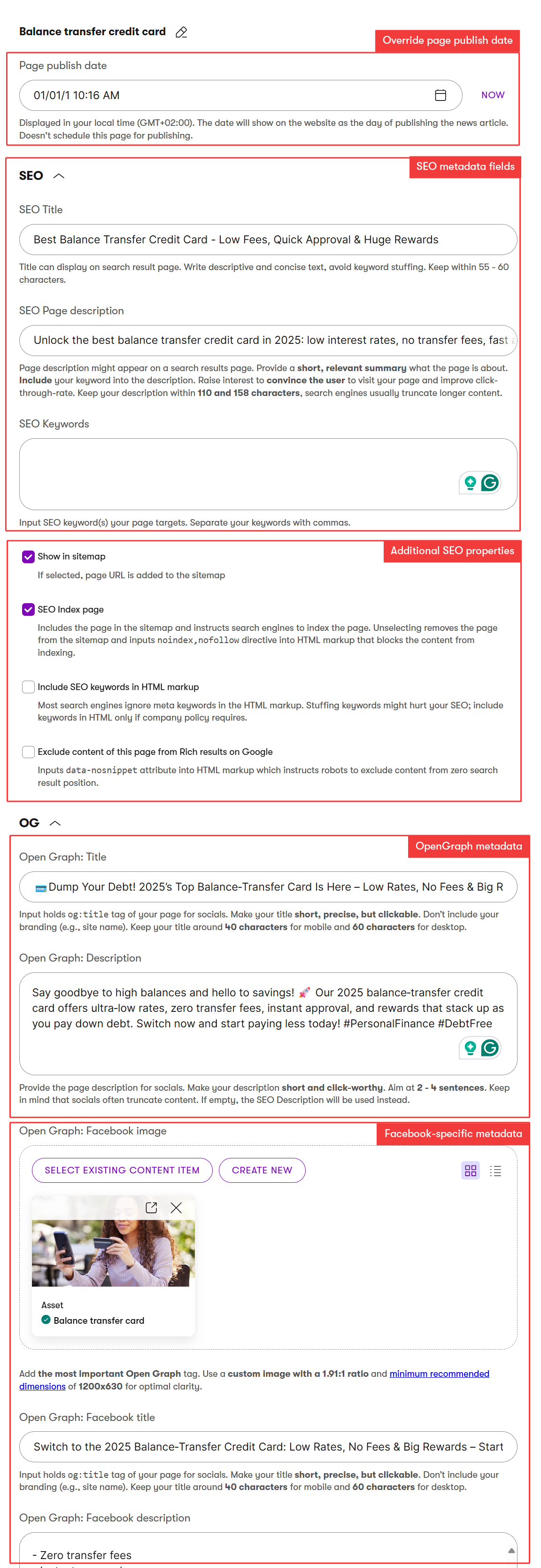
This approach ensures your atomic content remains clean, reusable, and consistent while allowing your website to display it with the metadata and context needed for that channel.
How wrappers work in headless delivery
In headless scenarios, editors can create a headless wrapper for their content. The headless wrapper references the reusable content items. It allows editors to add channel-specific calls to action, hero banners, or tracking tags needed for the app or headless site, without modifying the underlying structured data.
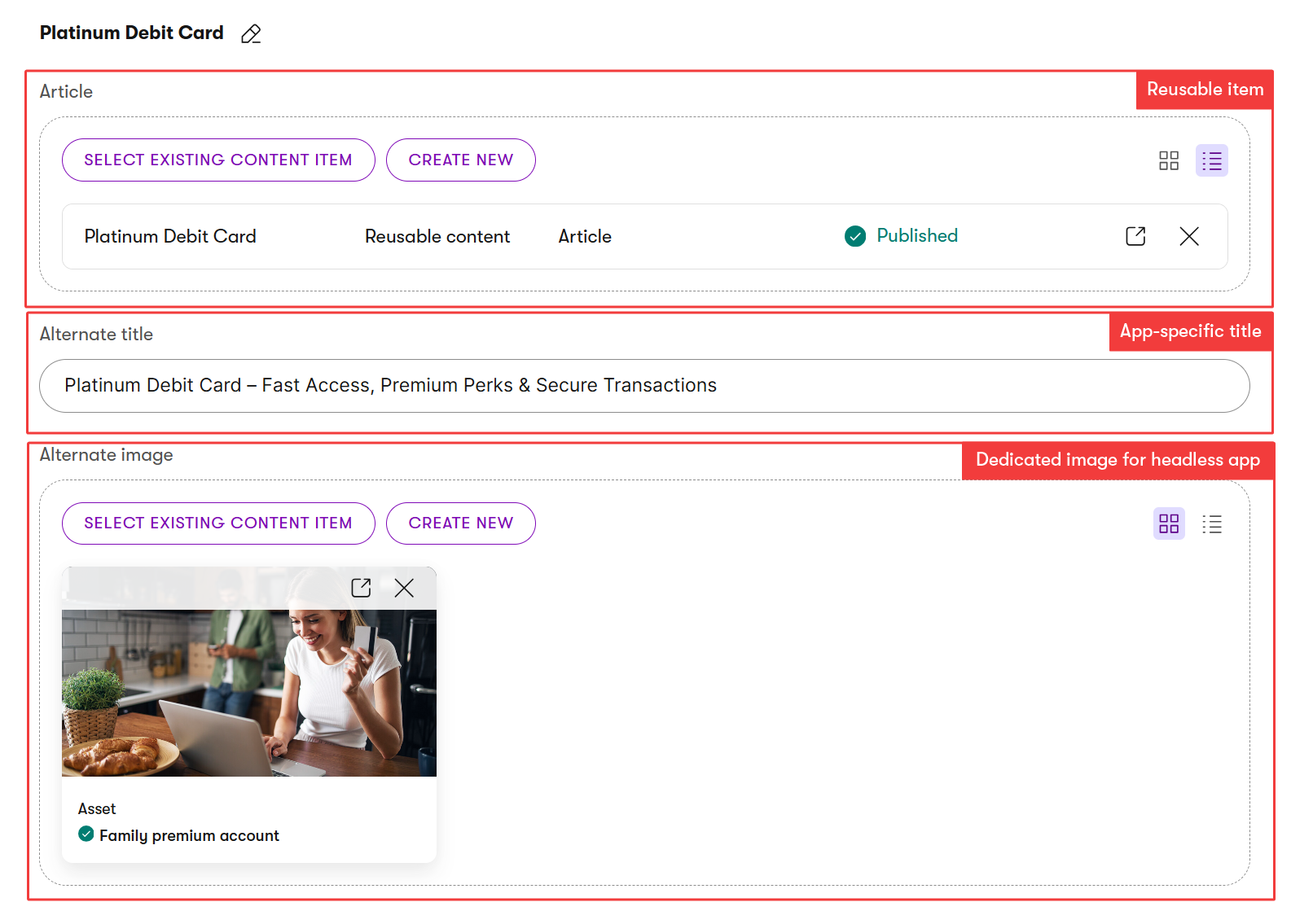
For example, the image above shows a headless Article content type where the marketing team can add a seasonal CTA to the headless wrapper while the Product content remains unchanged in the Content hub. We discuss approaches to designing headless content in a dedicated guide.
Why content wrappers matter
Page (or content) wrappers allow you to:
- Maintain a single source of truth for your core content while adapting it for each channel’s needs.
- Avoid duplicating data just to add metadata necessary for a particular channel.
- Support flexible delivery across channels, ensuring your website, headless apps, and other customer touch points present the same content.
- Empower editors to enhance content items within their channel without changing the underlying core reusable data.
This approach makes your content model scalable and helps marketing, product and other teams collaborate to deliver content across different digital marketing channels.
Plan content lifecycle workflows and governance
The atomic model works best with clear rules for who owns which content. Different teams can manage specific reusable parts without stepping on each other’s work. For example, product managers can own and update the core product data, the marketing team can manage and optimize campaign CTAs, and the legal team maintains disclaimers to ensure compliance.
Using workspaces, page permissions, role permissions, and content workflows in Xperience helps you enforce this structure.
You can set up workspaces so each team only sees and edits the content they are responsible for. Combine workflows with granular permissions to ensure editors can access content they are supposed to work with without accidentally modifying it. Content workflows add an approval layer, ensuring changes are reviewed by the right people before they go live.
Good governance ensures that editors don’t accidentally break the structure or duplicate data across the system. It keeps your content model clean and sustainable, enabling your teams to collaborate confidently while protecting the integrity of your reusable content.
Know the challenges before you start
Atomic models are powerful but require more planning. This means that they work well for mostly experienced teams. Teams must cooperate during the content modeling sessions to ensure the project’s success. They need to agree on many different things, from content composition to the content governance rules, up to a detailed understanding of the content lifecycle. Editors working with the atomic content model will also need detailed training on how to compose larger content types from smaller linked items.
If the project operates across several channels from the beginning, it is worth investing the time and other resources to define a reusable atomic content model upfront.
Manage the complexity in planning and modeling sessions
Atomic content requires careful planning to define reusable content types, naming conventions, and relationships between them. The model can become confusing and slow to implement without an explicit agreement between business stakeholders, content managers, and developers. They need to agree on how they’ll compose different content types, which content needs to be reusable or one-off, and especially the content model handover workflows. Editors need to test if the way they’ll compose the content from atomic pieces using the suggested approach will work for them.
Start by identifying high-value, obviously reusable content pieces, such as content types described in schema.org. Then break down these large content types into smaller content types that still represent semantic units, for example, benefits, features, author bios, and CTAs, before breaking all content into atomic pieces.
Workshop your content model with stakeholders to identify reusable elements early and map clear ownership before building the project.
Share a test environment with the stakeholders from the content teams during the initial implementation, where they can experiment with the suggested model. This will help teams gain experience with what working with reusable content looks like in Xperience and experience the benefits of reusing, not duplicating, content.
Avoid making the model excessively granular
It is easy to overdo atomic modeling, create too many micro content types, and multiply the complexity of the content model without meaningful benefits. Each project differs, and you need to find a balance between reusability and practical editorial workflows.
An easy way to test the complexity is to require your developers (and other solutions architects) to create and then adjust several content items to test the editing experience. Once they put themselves in the editor’s shoes, they’ll discover any friction in the suggested flow and identify where to optimize it.
Manage linked dependencies during publishing
Atomic content creates dependencies between content items. If an editor updates a reusable benefit, it impacts all products using that benefit. Xperience supports cascade publishing, which allows publishing all unpublished linked (or associated) items with the content item editors work with. Implement review and approval processes for shared content items, so updates to reusable elements are deliberate and vetted by the right stakeholders before they appear across channels. This protects consistency while supporting flexibility for updates.
While cascade publishing helps ensure consistent content, editors might also accidentally publish unintended changes. This happens when teams don’t align on governance, and the project doesn’t have correctly set content management workflows and workspaces.
Consider potential query and performance issues
Composing content dynamically from multiple linked items at several levels will require additional query optimization and caching strategies during delivery, especially on high-traffic applications with complex content relationships.
Your developers will need to ensure that they poll exactly the data they need to a specific level to avoid query performance hits. Work closely with developers to optimize queries and caching for your atomic content structures. Atomic models can lead to more complex queries, and planning performance strategies early ensures your site or app remains fast and scalable. If the content types share the same content properties, consider storing them in reusable field schemas to consolidate the content type’s complexity and improve querying.
Define safeguards in content governance
Atomic content modeling works best when teams have clear roles and governance responsibilities. Define workspace and permission configurations to avoid accidental content modifications.
Collaborate with the stakeholders to define clear ownership and workflows for reusable content. Ensure each team knows which content they manage, who approves changes, and how updates flow across linked items. This reduces friction and prevents conflicts when editors reuse content across multiple channels.
Address the editorial learning curve
Composing pages or products from multiple linked items can initially feel fragmented, especially if the team is used to working with monolithic, page-based content types. Editor teams, not just the stakeholders on the content modeling team, will need training sessions and a sandbox environment to learn how to build content from smaller, linked content items instead of editing almost everything in one place.
Make sure there’s enough time in the project timeline to train editors and reviewers on working with their content items. Editors need to understand how to assemble pages and other content artifacts using reusable content pieces and what the new workflow will look like. Use explanation texts or tooltips to provide editor guidance, context, and instructions to clarify what data and format they should input into different content types and what the output will look like once the content is displayed. And supply extensive documentation as part of the project deliverables.